Истина где‑то рядом — ищем аномалии с Python. Часть 2: практика
В первой части статьи мы обсудили, какие бывают аномалии в реальном мире, почему важно их находить и как для этого используется машинное обучение. Теперь попробуем извлечь из аномалий реальную пользу и применим наши знания на практике с помощью нескольких примеров на Python.
Начнём с того, что визуально оценим набор данных и посмотрим, сможем ли мы найти аномалии. Файл Jupyter Notebook с нижеизложенным кодом можно найти здесь.
Для начала создадим синтетический набор данных, который будет содержать только два столбца:
— ФИО сотрудников организации (для 100 человек)
— их ежемесячная заработная плата (в долларах США) в диапазоне от 1000 до 2500.
Чтобы сгенерировать похожие на настоящие имена, мы будем использовать Python-библиотеку Faker, а для зарплаты подойдёт привычная numpy. После этого объединим созданные столбцы в Pandas DataFrame.
Примечание: не пренебрегайте работой с фиктивными наборами данных, это действительно важный экспериментальный навык!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# Импортируем необходимые пакеты import pandas as pd import numpy as np import matplotlib.pyplot as plt # Раскомментируйте следующую строчку, если используете Jupyter Notebook # %matplotlib inline # Use a predefined style set plt.style.use('ggplot') # Импортируем Faker from faker import Faker # Убеждаемся, что результаты воспроизводимые Faker().seed(4321) names_list = [] fake = Faker() for _ in range(100): names_list.append(fake.name()) # Убеждаемся, что результаты воспроизводимые np.random.seed(7) salaries = [] for _ in range(100): salary = np.random.randint(1000,2500) salaries.append(salary) # Создаём pandas DataFrame salary_df = pd.DataFrame( {'Person': names_list, 'Salary (in USD)': salaries }) # Печатаем часть DataFrame print(salary_df.head()) |
Давайте вручную изменим зарплату двух человек, чтобы создать выбросы. В реальности это может произойти по ряду причин, например, из-за невнимательности бухгалтера или сбоя программного обеспечения.
|
1 2 3 4 5 6 |
salary_df.at[16, 'Salary (in USD)'] = 23 salary_df.at[65, 'Salary (in USD)'] = 17 # Убеждаемся, что зарплата изменилась print(salary_df.loc[16]) print(salary_df.loc[65]) |
Теперь можно начать эксперименты.
Видеть значит верить: находим аномалии глазами
Подсказка: ящики с усами великолепны!
Как упоминалось в предыдущей статье, появление аномалий напрямую зависит от генерации самих данных. Рассмотрим немного базовой статистики (минимальное значение, максимальное, значение 1-го квартиля и т. д.) в виде ящика с усами (диаграммы размаха):
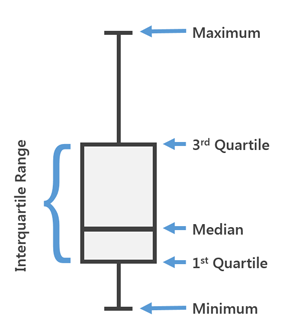
|
1 2 3 |
# Генерируем ящик с усами salary_df['Salary (in USD)'].plot(kind='box') plt.show() |
Мы получим:
Обратите внимание на маленький кружок в самом низу. Он сразу даёт понять, что что-то не так, потому что сильно отличается от остальных данных.
Как насчёт гистограмм?
|
1 2 3 |
# Генерируем гистограмму salary_df['Salary (in USD)'].plot(kind='hist') plt.show() |
Результат:
На графике выше мы тоже видим отклоняющуюся ячейку. Ось Y даёт понять, что зарплата искажена только у двух сотрудников.
Какой же способ сразу подтвердит наличие аномалий в наборе данных? Давайте посмотрим на минимальное и максимальное значение столбца «Заработная плата» (Salary):
|
1 2 3 |
# Минимальная и максимальная зарплата print('Minimum salary ' + str(salary_df['Salary (in USD)'].min())) print('Maximum salary ' + str(salary_df['Salary (in USD)'].max())) |
Получим:
|
1 2 |
Minimum salary 17 Maximum salary 2498 |
Минимальное значение явно отклоняется от того, что было задано раньше (1000 долларов). Следовательно, это действительно аномалия.
Примечание: хотя наш набор данных содержит только один признак (зарплату), в настоящих датасетах аномалии могут встречаться в разных признаках. Но даже там такие визуализации помогут вам их обнаружить.
Кластерный подход для обнаружения аномалий
Мы выяснили, что кластеризация и поиск аномалий тесно связаны, хоть и служат разным целям. Но кластеризацию можно использовать для детектирования выбросов. В этом разделе мы рассмотрим аномалии в виде групп похожих объектов. Математически их схожесть измеряется такими функциями, как евклидово расстояние, манхэттенское расстояние и т. д. Евклидово расстояние — самое распространённое, поэтому остановимся на нём подробнее.
Очень короткая заметка о евклидовом расстоянии
Если в двумерном пространстве есть n точек (см. следующий рисунок) и их координаты обозначены (x_i, y_i), то евклидово расстояние между любыми двумя точками x1, y1 и x2, y2 равно:
Для кластеризации мы будем использовать метод k-средних. Начнём:
|
1 2 3 4 5 6 |
# Конвертируем зарплату в массив numpy salary_raw = salary_df['Salary (in USD)'].values # Для совместимости со SciPy salary_raw = salary_raw.reshape(-1, 1) salary_raw = salary_raw.astype('float64') |
Теперь импортируем модуль kmeans из scipy.cluster.vq. SciPy (Scientific Python) — это библиотека для различных научных расчётов. Применим kmeans к salary_raw:
|
1 2 3 4 5 6 |
# Импортируем cluster и kmeans из SciPy from scipy import cluster from scipy.cluster.vq import kmeans # Передаём данные и число кластеров в kmeans() centroids, avg_distance = kmeans(salary_raw, 4) |
Во фрагменте выше мы указали в kmeans данные о зарплате и количество кластеров, по которым хотим сгруппировать точки. centroids — это центроиды, сгенерированные kmeans, а avg_distance — усреднённое евклидово расстояние между ними и точками. Давайте извлечём наши кластеры с помощью метода vq(). Его аргументы это:
— точки данных
— центроид, сгенерированный алгоритмом кластеризации.
Метод возвращает группы точек (кластеры) и расстояния между точками и ближайшими кластерами.
|
1 2 3 4 5 6 7 8 |
# Получаем кластеры и расстояния groups, cdist = cluster.vq.vq(salary_raw, centroids) # Рисуем график plt.scatter(salary_raw, np.arange(0,100), c=groups) plt.xlabel('Salaries in (USD)') plt.ylabel('Indices') plt.show() |
Теперь вы точно видите аномалии. Итак, несколько моментов, которые необходимо учитывать перед обучением модели:
- Тщательно изучите данные — взгляните на каждый признак в наборе, соберите статистику.
- Постройте несколько полезных графиков (как показано выше), так вам будет легче заметить отклонения.
- Посмотрите, как признаки связаны друг с другом. Это поможет выбрать наиболее значимые из них и отказаться от тех, что не влияют на целевую переменную (не коррелируют с ней).
Вышеуказанный метод обнаружения аномалий — пример обучения без учителя. Если бы у нас были метки классов, мы могли бы легко превратить процесс в обучение с учителем и рассматривать его как проблему классификации.
А почему бы и нет?
Обнаружение аномалий как проблема классификации
Для этого нам понадобится добавить к набору данных целевые переменные (метки). Сначала присвоим всем записям нулевые метки, а затем вручную отредактируем два значения для аномалий (установим их как 1):
|
1 2 3 4 5 6 7 8 9 |
# Устанавливаем метки для всех объектов salary_df['class'] = 0 # Вручную исправляем метки для аномалий salary_df.at[16, 'class'] = 1 salary_df.at[65, 'class'] = 1 # Проверяем print(salary_df.loc[16]) |
Снова взглянем на датасет:
Теперь мы решаем задачу бинарной классификации. Будем искать выбросы, основываясь на подходе близости (proximity-based anomaly detection). Основная идея в том, что близость аномальной точки к её соседним точкам сильно отличается от близости других точек к их соседям. Если вам ничего не понятно, не пугайтесь — на наглядном примере всё станет ясно.
Для этого мы применим метод k-ближайших соседей и Python-библиотеку PyOD, специально предназначенную для детектирования выбросов.
|
1 2 |
# Импортируем модуль KNN из PyOD from pyod.models.knn import KNN |
Столбец “Person” для модели совершенно бесполезен, поскольку служит лишь идентификатором. Подготовим обучающую выборку:
|
1 2 3 4 5 6 7 |
# Разделяем значения зарплаты и метки классов X = salary_df['Salary (in USD)'].values.reshape(-1,1) y = salary_df['class'].values # Обучаем kNN-детектор clf = KNN(contamination=0.02, n_neighbors=5) clf.fit(X) |
Аргументы, переданные в KNN():
— contamination: количество аномалий в данных (в процентах), в нашем случае 2/100
— n_neighbors: число соседей, упитывающихся при измерении близости
Теперь получим прогнозируемые метки и оценку аномалий. Чем выше оценка, тем хуже данные. Для этого применим удобные функции PyOD:
|
1 2 3 4 5 |
# Получаем метки данных обучения y_train_pred = clf.labels_ # Оценка аномалий y_train_scores = clf.decision_scores_ |
Попробуем оценить KNN() относительно обучающей выборки с помощью функции evaluate_print():
|
1 2 3 4 5 |
# Импортируем утилиту для оценки модели from pyod.utils import evaluate_print # Оцениваем на обучающей выборке evaluate_print('KNN', y, y_train_scores) |
Получим:
|
1 |
KNN ROC:1.0, precision @ rank n:1.0 |
Видим, что KNN() достаточно хорошо работает на обучающих данных. Он выдаёт три метрики и их оценки:
— ROC
— точность
— доверительную оценку.
Примечание: при обнаружении аномалий всегда следует учитывать эти оценки, поскольку они дают наиболее полное представление об эффективности модели.
У нас нет тестовой выборки, но мы можем сгенерировать примерное значение зарплаты:
|
1 2 |
# Зарплата в $37 (аномалия, верно?) X_test = np.array([[37.]]) |
Давайте проверим, может ли модель пометить это значение как выброс:
|
1 2 |
# Проверим, что спрогнозирует модель с этим значением clf.predict(X_test) |
Вывод должен быть: array([1])
Видим, что модель не ошиблась. Проверим, как она работает с нормальными данными:
|
1 2 3 4 5 |
# Зарплата в $1256 X_test_abnormal = np.array([[1256.]]) # Прогноз clf.predict(X_test_abnormal) |
Вывод: array([0])
Модель отметила значение как обычную точку данных.
На этом мы завершаем исследование аномалий и переходим к заключению.
Проблемы и дальнейшие исследования
Мы познакомились с миром аномалий и некоторыми его особенностями. Прежде чем подвести итоги, неплохо было бы обсудить несколько проблем, которые затрудняют задачу поиска выбросов:
— Эффективное разделение данных на «нормальные» и «аномальные»: иногда трудно найти границу, которая будет служить индикатором выбросов, особенно в задачах из совершенно разных предметных областей. Придётся либо тратить много времени на изучение данных, либо консультироваться с соответствующими специалистами.
— Понимание разницы между шумом и аномалиями: если принять выбросы за шум или наоборот, то можно изменить весь ход процесса обнаружения аномалий, поэтому следует уделять внимание этому вопросу.
Теперь поговорим о том, как вам продвинуться в исследованиях и улучшить качество данных. Вот несколько тем, которые мы не затронули в статье:
— Обнаружение аномалий во временных рядах: очень важная область, поскольку временные ряды широко распространены.
— Методы поиска аномалий, основанные на глубоком обучении: нейросети тоже могут помогать в поиске выбросов, и эта тема уже давно и активно исследуется.
— Другие сложные методы: здесь мы рассматривали только поиск точечных аномалий. Но есть ряд алгоритмов для обнаружения контекстуальных и коллективных аномалий. Более подробную информацию о них можно найти в книге “Data Mining. - Concepts and Techniques (3rd Edition)”.
Надеемся, что эта статья помогла вам немного погрузиться в фантастический мир поиска аномалий. Подготовка данных — один из самых непростых и кропотливых процессов в машинном обучении. И теперь вы стали на шаг ближе к тому, чтобы научиться обрабатывать их максимально эффективно. Если у вас возникли какие-то вопросы — не стесняйтесь задавать их в комментариях, мы обязательно ответим и поможем разобраться.
С оригинальной статьёй можно ознакомиться в блоге floydhub.com.









