Как ускорить Data Science с помощью GPU
Аналитикам данных нужны вычислительные мощности. Обрабатываете ли вы большой датасет в Pandas или перемножаете множество матриц с Numpy — вам понадобится производительная машина, чтобы выполнить работу в разумные сроки. В этой статье мы наглядно покажем, как с помощью GPU можно ускорить обработку данных в десятки раз.
За последние несколько лет библиотеки Python, предназначенные для Data Science, довольно хорошо научились использовать возможности CPU. Например, Pandas отлично справляется с обработкой наборов данных, размер которых превышает 100 ГБ. А если у вашей машины недостаточно ОЗУ, вы всегда можете использовать удобные функции, разбивающие данные на небольшие пакеты и обрабатывающие по одному фрагменту за раз.
GPU vs CPU: параллельная обработка
CPU лучше справляются с процессами, где большую роль играет тактовая частота. Также стоит использовать его в задачах, которые нельзя реализовать на GPU. В свою очередь, графический процессор гораздо эффективнее выполняет программы, выигрывающие от параллельной обработки.
Большое влияние GPU оказывают на Deep Learning. Повторяющиеся вычисления, например, свёртку, можно ускорить с их помощью до 100 раз.
В Data Science тоже присутствуют многократно выполняемые операции, которые обрабатывают большие наборы данных с помощью таких библиотек как Pandas, Numpy и Scikit-Learn. На GPU выполнять эти операции достаточно просто.
Ускорение GPU с Rapids
Rapids — набор программных библиотек, предназначенных для ускорения Data Science за счет использования графических процессоров. Он генерирует низкоуровневый код CUDA для быстрого выполнения алгоритмов, оптимизированных на GPU, и в то же время имеет простую реализацию на Python.
Преимущество Rapids в том, что он хорошо интегрируется в библиотеки Data Science. Например, Pandas dataframe можно легко передать в Rapids и ускорить обработку на GPU. На рисунке ниже показано, как Rapids делает доступным низкоуровневое ускорение, сохраняя при этом высокоуровневую реализацию.
Rapids использует несколько Python-библиотек:
— cuDF: dataframes для GPU. Поддерживает практически те же способы обработки данных, что и Pandas.
— CuML: библиотека для машинного обучения. Содержит множество алгоритмов ML, которые есть в Scikit-Learn.
— cuGraph: обработка графов на GPU. Поддерживает много основных алгоритмов анализа графов, включая PageRank.
Гайд по использованию Rapids
Установка
Теперь вы увидите Rapids в действии!
В качестве примера мы запустим простой код на сервере с GPU NVIDIA Tesla V100.
Для демонстрации мы решили запустить код на двух GPU NVIDIA Tesla V100 и сравнить время выполнения с Nvidia Data Science Work Station, которая работает на двух GPU NVIDIA Quadro RTX 8000.
Чтобы загрузить и запустить образ с Rapids и всем необходимым ПО, мы использовали следующие команды. В этом примере мы выбрали конфигурацию с Ubuntu 18.04, CUDA 10.0 и Python 3.7. Вы можете поменять версии и скопировать команды для установки на сайте Rapids.
|
1 2 3 |
docker pull rapidsai/rapidsai:0.8-cuda10.0-runtime-ubuntu18.04-gcc7-py3.7 docker run --runtime=nvidia --rm -it -p 8888:8888 -p 8787:8787 -p 8786:8786 \ rapidsai/rapidsai:0.8-cuda10.0-runtime-ubuntu18.04-gcc7-py3.7 |
Заходим в директорию utils и запускаем JupyterLab:
|
1 2 |
cd utils ./start-jupyter.sh |
Переходим в JupyterLab.
Настройка данных
В этом примере мы рассмотрим модифицированную версию DBSCAN demo. DBSCAN - это алгоритм кластеризации, который может автоматически разбивать данные на группы без указания числа кластеров. Похожая реализация есть в Scikit-Learn.
Начнём с импортирования необходимых библиотек:
|
1 2 3 4 |
import os import matplotlib.pyplot as plt from matplotlib.colors import ListedColormap from sklearn.datasets import make_circles |
Функция make_circles создаст сложное распределение данных, напоминающее две окружности.
Зададим набор данных из 100 000 точек и отобразим его в виде графика:
|
1 2 3 4 5 |
X, y = make_circles(n_samples=int(1e5), factor=.35, noise=.05) X[:, 0] = 3*X[:, 0] X[:, 1] = 3*X[:, 1] plt.scatter(X[:, 0], X[:, 1]) plt.show() |
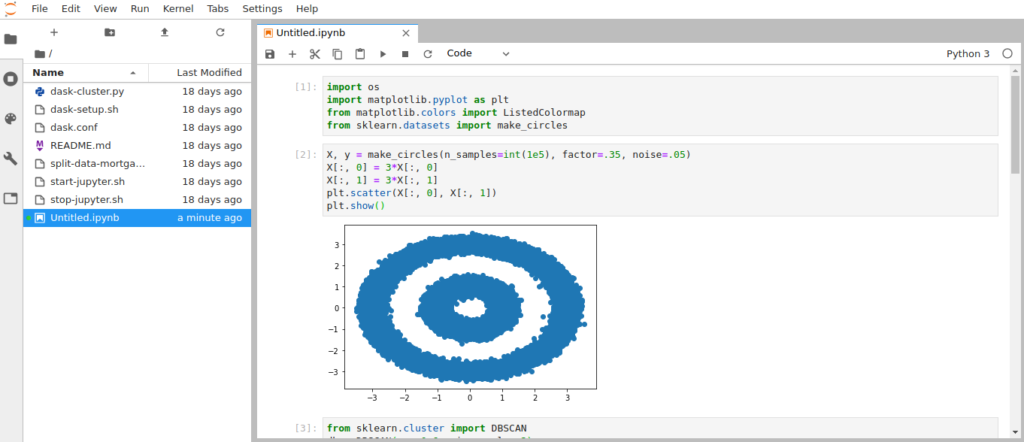
DBSCAN на CPU
Запустить DBSCAN на CPU можно с помощью Scikit-Learn. Импортируем его и настроим некоторые аргументы:
|
1 2 |
from sklearn.cluster import DBSCAN db = DBSCAN(eps=0.6, min_samples=2) |
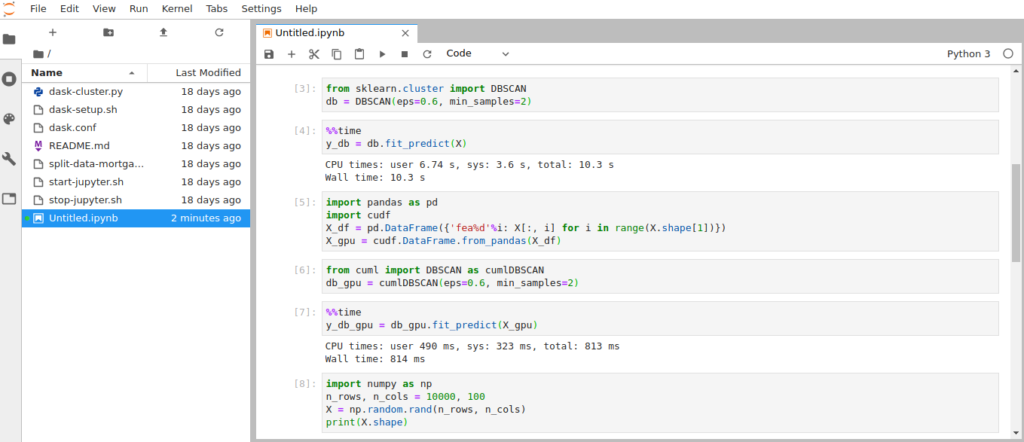
Теперь можем применить DBSCAN к нашим круговым данным. Параметр %%time перед функцией позволит Jupyter Notebook измерить время ее выполнения:
|
1 2 |
%%time y_db = db.fit_predict(X) |
Для 100 000 точек время выполнения на CPU составило 10.3 секунды. Получившиеся кластеры выглядят так:
DBSCAN с Rapids на GPU
А теперь пришло время ускориться!
Конвертируем наши данные в pandas.DataFrame и используем их для создания cudf.DataFrame. Это делается всего двумя командами:
|
1 2 3 4 5 |
import pandas as pd import cudf X_df = pd.DataFrame({'fea%d'%i: X[:, i] for i in range(X.shape[1])}) X_gpu = cudf.DataFrame.from_pandas(X_df) |
Затем импортируем и инициализируем версию DBSCAN из cuML для ускорения на GPU. Формат и параметры функции cuML-версии DBSCAN такие же, как и в Scikit-Learn.
|
1 2 |
from cuml import DBSCAN as cumlDBSCAN db_gpu = cumlDBSCAN(eps=0.6, min_samples=2) |
Наконец, запустим функцию прогнозирования для DBSCAN GPU и измерим время выполнения.
|
1 2 |
%% time y_db_gpu = db_gpu.fit_predict (X_gpu) |
Время выполнения на двух NVIDIA Tesla V100 снизилось до 814 миллисекунд! По сравнению с CPU ускорение получается 12-кратным, но чаще всего код таких программ не оптимизирован для выполнения на CPU. Поэтому сравним производительность с двумя GPU NVIDIA Quadro RTX 8000: они показывают результат в 4.22 секунды. Процессоры Tesla V100 по сравнению с Quadro RTX 8000 достигли ускорения в 5 раз.
Суперускорение с Rapids!
Степень ускорения, которую мы получаем с Rapids, зависит от количества обрабатываемых данных. Однако существует дополнительная задержка, связанная с передачей данных между CPU и GPU. Она становится менее существенной, когда мы обрабатываем большие датасеты.
Разберёмся на простом примере.
Создадим массив случайных чисел Numpy и применим к нему DBSCAN. При этом сравним скорость выполнения, увеличивая и уменьшая количество точек данных. Так мы увидим, как объем данных влияет на степень ускорения.
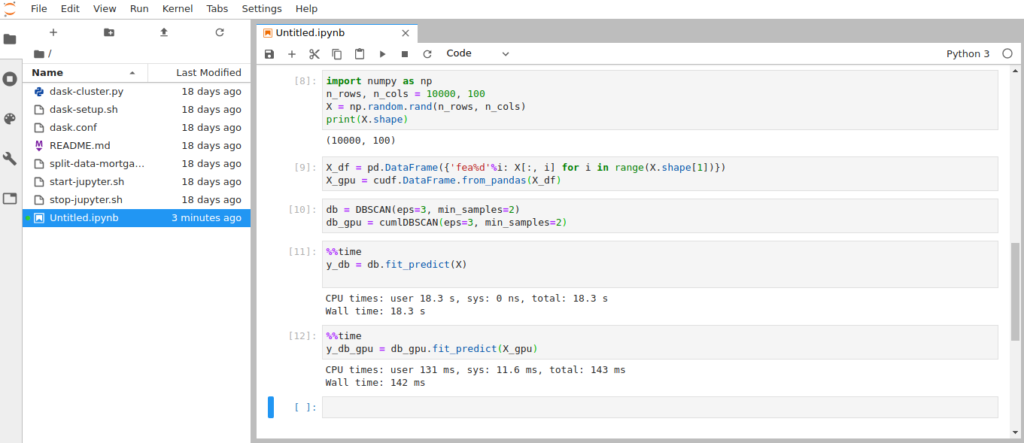
Пример кода для набора данных размером 10000х100 точек:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import numpy as np n_rows, n_cols = 10000, 100 X = np.random.rand(n_rows, n_cols) print(X.shape) X_df = pd.DataFrame({'fea%d'%i: X[:, i] for i in range(X.shape[1])}) X_gpu = cudf.DataFrame.from_pandas(X_df) db = DBSCAN(eps=3, min_samples=2) db_gpu = cumlDBSCAN(eps=3, min_samples=2) %%time y_db = db.fit_predict(X) %%time y_db_gpu = db_gpu.fit_predict(X_gpu) |
В примере датасет состоит из миллиона точек. На рисунке вы можете увидеть, что его обработка на GPU Tesla выполняется за 142 миллисекунды, а на CPU — 18.3 секунды. Quadro RTX справляется с той же задачей примерно за 1.5 секунды (оценка сделана по графику из статьи с помощью сравнения скоростей CPU), то есть Tesla оказалась быстрее неё почти в 11 раз.
Таким образом, с увеличением размера данных до определённой степени растёт и ускорение, получаемое с GPU.
Теперь вы знаете, какую высокую скорость обработки данных можно получить с мощными GPU. Для дальнейшего погружения в Data Science рекомендуем ознакомиться с книгой Python для сложных задач: наука о данных и машинное обучение (перевод книги Python Data Science Handbook).
С оригинальной статьёй и результатами работы программ на GPU NVIDIA Quadro RTX 8000 можно ознакомиться на сайте towardsdatascience.com.









